-
프런트엔드 AX 설계기 3편 — `done` 경계를 측정으로 설계한 이야기AI 엔지니어링 2026. 7. 1. 19:51728x90반응형
1. 도입부 (Why This Matters)
done은 안전해 보이는 단어다. 그런데 AI 보조 개발에서done은 두 번 위험하다 — 작업이 들어갈 때, 그리고 나온 뒤.나온 뒤부터 보자. 대부분의 PM 도구는 작업 상태를 단방향으로 본다.
specification → planned → in-progress → done. 한번done이면 끝. "완료된 작업은 완료된 채로 남는다"는 가정 위에 서 있다. 사람만 일하던 시절엔 버텼다. 그러나 AI 에이전트는 task 7을 구현하다 이미done인 task 2의 설계 결함을 드러내고, 당신은 의도를 실시간으로 바꾼다. 단방향 모델에는 무효화된done을 표현할 자리가 없다.들어갈 때도 함정이 있다. AI가 짠 코드를 사람이 다 읽을 수 없으니, AI가 AI의 코드를 리뷰해
done을 부여하는 게이트(LLM-as-judge)를 둔다. 여기서 두 직관이 작동한다. "리뷰 관점을 많이 볼수록 안전하다", "관점을 2개로 늘리면 비용도 2배(혹은 4배)." 측정해 보면 둘 다 틀렸다.두 함정의 공통 원인은 하나다. AI 워크플로에 대한 순진한 직관. 그리고 공통 처방도 하나다. 직관이 아니라 측정으로 설계한다. 이 글은
done의 두 경계를 그 원칙으로 설계한 기록이다. 읽고 나면 reverse transition 규칙·un-archive 절차(나오기)와, 리뷰 게이트를 측정으로 보정하는 법(들어가기)을 자기 팀에 옮길 수 있다. 예상 소요 약 12분.한 가지 관점:
done상태든 게이트 verdict든, 결국 사람의 의도와 에이전트 사이의 인터페이스다. 에이전트는 매 실행마다 이 신호를 읽고 자기 행동을 정한다. 신호를 정합하게 설계하는 일은 프런트엔드가 늘 해온 일(상태 모델링)을 에이전트라는 새 표면으로 넓힌 것이다. AX(Agent Experience, 에이전트를 위한 인터페이스 설계)는 곁다리가 아니라 넓어진 본업이다.2. 핵심 개념 (What & Why)
원칙부터 박아 두자. AI 워크플로에서 직관은 측정 없이는 자주 틀린다. 이 원칙을
done경계의 양쪽에 각각 적용한 것이 이 글의 두 축이다.나오기 — 양방향 라이프사이클. forward 경로(
specification → … → done)뿐 아니라 reverse 경로(done → in-progress → planned)를 1급 시민으로 모델링한다. 무효화된 task엔rework_required: true를 달고, 그 역전을 상위 spec, 다시 상위 initiative로 전파한다.들어가기 — 측정으로 보정한 리뷰 게이트. writer 에이전트가 짠 코드를 분리된 reviewer 에이전트가 평가해
PASS / FAIL / N/A를 낸다. 리뷰는 여러 관점(lens)으로 본다(예: 로직 정확성, 계약·에지케이스). 관점 개수, 비용, verdict의 의미 — 이 knob들을 직관이 아니라 golden-set 측정으로 정한다.왜 하필 AI에서 중요한가. 나오는 쪽은, 에이전트가 spec을 자주 무효화하기 때문이다(빈도 자체는 벤치마크가 아니라 운영 관찰 — 추정으로 읽어 달라). 단방향 모델은
done을 종착역으로 보기에, 무효화가 나면 실무자는 (a)done을 유지한 채 메모만 남기거나 (b) 새 task를 만든다. 둘 다 dependency trace를 잃는다. 들어오는 쪽은, AI가 AI를 평가하면 자기 출력에 점수를 후하게 주는 self-preference bias가 끼고, "관점은 많을수록 좋다" 같은 미보정 직관이 비용만 키우기 때문이다.일반 이슈 트래커의
reopen과 다른 점도 여기 있다. reopen은 단일 티켓 하나를 다시 여는 동작이다. 여기서 다루는 건 task·spec·initiative 세 계층에 걸친 상태 정합성의 전파다.3. 동작 원리 ① —
done에서 나오기: reverse transition단방향이 깨지는 지점
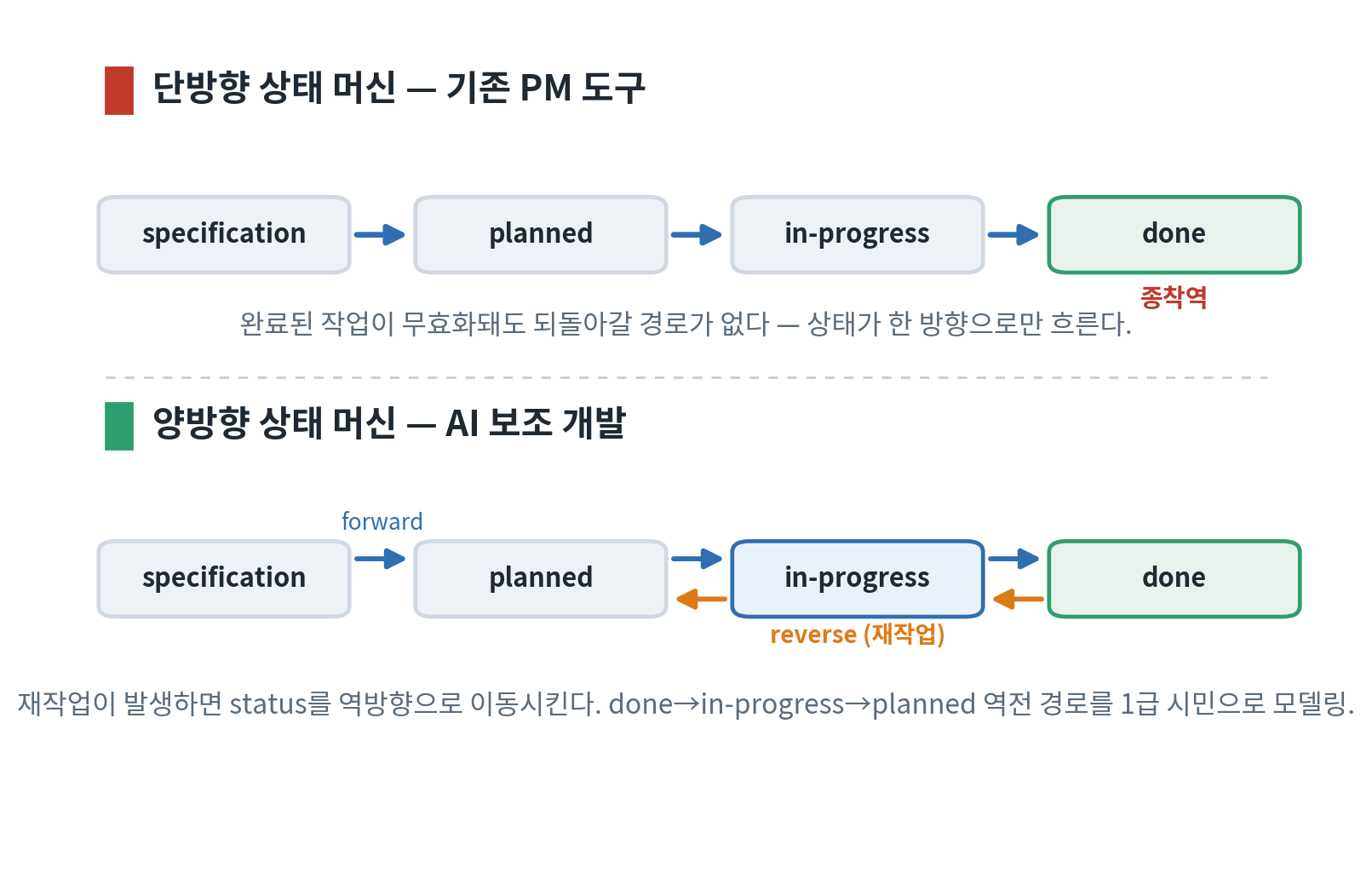
상태 값부터. spec은
specification(명세만) →planned(task 분해 완료) →in-progress(최소 1개 task 시작) →done(전 task 완료·동기화). task는pending→in-progress→done. 핵심은 거꾸로 가는 규칙이다.reverse transition 규칙 — highest-applicable
무효화된 task가 작업을 spec으로 되돌릴 때, spec의
status도 "할 일이 남았음"을 반영하도록 역전돼야 한다. 규칙은 위에서부터 가장 먼저 들어맞는 것 하나를 적용한다.
- 어떤 task가
pending으로 되돌아가고(rework) 다른 task 중in-progress가 하나라도 있으면 → specstatus: in-progress. - 어떤 task가
pending으로 되돌아갔는데in-progress인 task가 하나도 없으면 → specstatus: planned. - 변경이 원래
pending이던 task만 무효화한다면 → spec status는 움직이지 않는다.
진행도가 높은 쪽(in-progress 존재)부터 평가해 내려가면 모호함 없이 단일 결과가 나온다. 역전의 바닥은
planned다 —specification까지는 내려가지 않는다(그림 1에서 reverse 화살표가planned에서 멈추는 이유). 이때 무효화된 task는status: pending과rework_required: true를 항상 함께 가지며,depends_on으로 묶인 하위 작업까지 영향이 추적된다.3-tier 캐스케이드와 un-archive
진짜 흥미로운 결과는 한 계층 위에서 나타난다. 여러 spec을 묶는 대형 작업 단위를 initiative라 하자(예: 플랫폼 재작성). 모든 슬라이스가
done이면 initiative는done이 되고 파일이 아카이브 폴더로 이동한다. 그런데 그중 한 spec이 reverse 되어 all-done 임계선이 깨지면?
작은 rework 한 번이 3-tier를 거슬러 올라간다. task가
done → pending, spec이done → in-progress, initiative가done → active로 un-archive 된다. 파일은archive/{YYYY}/{MM}/에서 active 루트로git mv되고, 내부 마크다운 링크의 상대 경로(..세그먼트 수)까지 재계산된다. 상태 머신이 한 계층에서만 양방향인 게 아니라 역전이 위로 캐스케이드 된다는 점이 이 설계의 핵심이다.놓치기 쉬운 에지 케이스
- Drift Gate 타이밍: spec과 실제 diff의 정합성 검증은 반드시
done/아카이브 이전에 돌려야 한다. 아카이브 된 spec에서는 검증이 스스로 건너뛰기 때문에, 사후에 돌리면 아무것도 못 잡는다. - 완료 정리는 자동이 아니다: 모든 task가
done이어도 시스템은 정리를 제안할 뿐 자동 실행하지 않는다. 배포·후속 PR이 남았으면 사용자가 거절할 수 있어야 한다. - reverse는 별도 게이트가 없다: 역전 전파와 un-archive는 rework 결정의 부수 효과다. 사용자 확인은 이미 rework 시점에 받았다.
4. 동작 원리 ② —
done으로 들어가기: 측정으로 보정한 리뷰 게이트writer와 reviewer를 분리한다

LLM-as-judge의 첫 함정은 self-preference bias다. 자기가 쓴 코드를 자기가 채점하면 점수를 후하게 준다. 그래서 코드를 짠 writer와 리뷰하는 reviewer를 다른 호출로 분리한다. 초기 분리 실험에선 self-scoring 인플레가 눈에 띄게 줄고 결함을 잡아내는 recall이 약 2배가 됐다(초기 측정치이니 방향성으로 읽되, 분리 자체는 구조적으로 옳다). 핵심은 점수가 아니라 누가 평가하는가를 바꾸는 구조다.
관점(lens) 개수는 직관이 아니라 측정으로
리뷰를 단일 패스로 한 번 보는 대신, 서로 다른 관점(lens)으로 병렬 평가한 뒤 merge 한다. 그러면 "관점은 많을수록 좋다"는 직관이 고개를 든다. 측정하면 그렇지 않다.

관점을 1개에서 2개로 늘릴 때 recall이 크게 오르고, 2개에서 knee가 꺾여 3~6개는 평탄했다(수확 체감). 측정 정직성을 한 겹 더 얹자면, 초기 directional 스윕은 더 큰 폭을 시사했지만 표본이 얇았다(thin-n). planted ground-truth로 통제 재측정하니 recall 81% → 88% (+7pp, pooled), 변별이 필요한 fixture에선 +10pp였다. 직관만 틀리는 게 아니라 통제 없는 측정도 과장한다 — 그래서 헤드라인은 통제 수치로 잡는다.
비용 동률 반전 — 호출 수가 안 변한다
여기서 자연스러운 우려가 나온다. "관점 2개 × 단가 2 배면 게이트 비용이 4배 아닌가?" 실측은 동률이었다. 2-lens 패널이 단일 invocation 안에서 돌기 때문에 LLM 호출 수 자체가 변하지 않는다. 비용 모델을 "관점 수"가 아니라 "호출 수"로 잡으면 사라지는 우려였다 — 이것도 측정 전엔 보이지 않았다.
verdict의 의미를 고정한다 — precision 가드와 N/A 회귀
정밀도(precision)는 cap-sweep 전 구간에서 유지됐다. 즉 게이트를 조이는 가드는 발견 개수의 상한(cap)이 아니라 confidence-floor(확신 임계)여야 한다는 뜻이다. 그리고 디버깅 루프 하나. lens-panel로 프레이밍을 바꾸자, 사소한 diff를
PASS가 아니라N/A(평가 불능)로 밀어내는 회귀가 생겼다. golden-set이 이걸 잡아냈고, "finding 없음 = PASS, N/A는 평가 불능 전용"으로 verdict 의미를 고정해 고쳤다. 게이트의 출력 신호가 흔들리면 그 신호를 읽는 다음 단계(=done전환)가 통째로 오염된다.5. 실무 적용 (Practical Examples)
✅ 권장 패턴 (Good Practice)
나오기. 무효화된 task는 상태를 정직하게 역전시키고 플래그로 표식 한다.
# task-2-token-refresh.md (frontmatter) --- task: 2 title: 토큰 갱신 처리 status: pending # done에서 역전 rework_required: true # pending과 항상 페어 depends_on: [1] # 하위 영향 추적 경로 ---# spec.md (frontmatter) --- feature: auth-refresh status: in-progress # 다른 task가 in-progress라 rule 1 적용 (done→in-progress) ---들어가기. 게이트는 네 가지를 지킨다. writer ≠ reviewer로 self-bias를 막고 · knob(관점 수 등)은 golden-set 측정으로 정하고(knee에서 멈춘다) · 비용은 단일 invocation으로 호출 수를 고정하고 · verdict 의미를 고정한다(
finding 없음 = PASS,N/A는 평가 불능 전용, 가드는 confidence-floor).❌ 안티패턴 (Anti-Pattern)
# 안티패턴 — done을 유지한 채 메모만 남김 --- task: 2 status: done # 실제로는 재작업 필요한데 done # note: "나중에 토큰 로직 고쳐야 함" ← 대시보드는 이걸 모른다 ---나오는 쪽에서
done을 방치하면 대시보드가 거짓말을 하고, 새 task로 갈아 끼우면 의존성·히스토리가 끊긴다. 무엇보다 에이전트가 다음 실행에서 stale 한done을 신뢰해 잘못된 전제로 코드를 짠다.들어오는 쪽의 안티패턴도 대칭이다. "더 많은 lens = 더 안전"이라 믿고 관점을 무한정 늘리면 knee 너머에선 효과는 평탄한데 복잡도만 오른다. writer가 자기 코드를 채점하게 두면 self-bias로 게이트가 물러지고, 사소한 diff를
N/A로 처리하면 게이트가 사실상 무력화된다. 공통점은 하나 — 측정 없이 knob을 만진다.🔍 실행 결과
나오는 쪽에선 토큰 로직 한 줄 수정이라는 작은 rework가 task
pending(+rework_required) → specin-progress→ 아카이브 됐던 initiativeactive복귀(파일이 active 루트로)로 캐스케이드 되고, 대시보드에서rework_requiredtask가 최상단 정렬로 다시 보인다. 들어오는 쪽에선 관점을 측정에 따라 2개로 고정해 비용을 호출 수 기준 동률로 유지하고, golden-set이 verdict 회귀(PASS→N/A)를 사전에 포착한다. 양쪽 모두 상태가 현실과 어긋나지 않는다.6. 장단점 및 고려사항
장점 단점 ✓ done양쪽 경계가 현실과 일치 — 대시보드·게이트가 거짓말하지 않음✗ 상태 머신 복잡도 상승(역방향 규칙·전파) ✓ 에이전트가 stale한 done을 신뢰하지 않음✗ un-archive 같은 드문 경로까지 구현·테스트 필요 ✓ task·spec·initiative 3-tier 정합성 보장 ✗ 게이트 보정에 golden-set 구축·유지 비용 ✓ self-bias 차단 + knob을 측정으로 정해 비용 동률 ✗ "측정 먼저" 규율이 팀에 자리잡는 학습 곡선 실무 도입 체크리스트:
- reverse 규칙은 highest-applicable 단일 진입점으로 구현한다(여러 if를 흩뿌리지 말 것).
rework_required: true는 항상status: pending과 페어로만 존재하게 강제한다.- 정합성 검증(drift)·완료 정리는
done전환 이전 / 사용자 확인 게이트를 유지한다. - 리뷰 게이트는 writer ≠ reviewer, 관점 수는 knee까지만, 비용은 호출 수로 센다.
- verdict 의미를 고정하고(
finding 없음 = PASS,N/A전용), 회귀는 golden-set으로 잡는다.
7. 핵심 3줄 요약
- AI 보조 개발에서
done은 들어갈 때와 나온 뒤 두 번 위험하고, 두 함정 모두 순진한 직관에서 온다. - 나오는 쪽은 reverse transition을 1급 시민으로 두어 task→spec→initiative로 역전을 캐스케이드(un-archive)하고, 들어오는 쪽은 writer/evaluator 분리·관점 수·비용·verdict를 측정으로 보정한다.
- 한 문장으로:
done경계는 직관이 아니라 측정으로 설계한다.
첫 단계는 가볍다. spec/task 템플릿에
rework_required와 reverse 규칙 세 줄을 넣고 대시보드 정렬에 rework 우선순위를 더하라(나오기). 리뷰 게이트가 있다면 작은 golden-set부터 만들어 "관점 하나 더"가 정말 recall을 올리는지 한 번 측정해 보라(들어가기). 직관이 틀리는 지점을 한 번 보면 규율이 생긴다.2026.06.19 - [AI 엔지니어링] - 프런트엔드 AX 설계기 2편 — 에이전트를 '자율 실행'에서 '명시적 동의'로
반응형'AI 엔지니어링' 카테고리의 다른 글
프런트엔드 AX 설계기 5편 - 테스트를 지워 초록불을 만드는 AI (0) 2026.07.06 프런트엔드 AX 설계기 4편 - LLM-as-judge는 왜 "다른 에이전트"가 채점해야 하는가 (0) 2026.07.03 프런트엔드 AX 설계기 2편 — 에이전트를 '자율 실행'에서 '명시적 동의'로 (0) 2026.06.26 프런트엔드 AX 설계기 1편 — AI 에이전트 설정을 4개 레이어로 쪼갠 이유 (0) 2026.06.24 프런트엔드 AX 설계기 0편 — 레거시 3개와 차세대 FE를 위한 워크플로우 설계기 (0) 2026.06.19 - 어떤 task가